
Self-Hosted LLM Stack: Production-Ready AI ohne Vendor Lock-in
Florian Wolf zeigt beim KI Klub Werder, wie du KI-Systeme selbst hostest – mit voller Datenkontrolle, ohne Cloud-Abhängigkeit
ChatGPT, Claude & Co. sind praktisch – aber jede Anfrage schickt deine Daten zu OpenAI, Anthropic oder Google. Für Unternehmen, die DSGVO-konform arbeiten wollen, sensible Daten verarbeiten oder einfach digitale Souveränität ernst nehmen, ist das eine Herausforderung.
Florian Wolf, CTO bei enersis climate intelligence Suisse AG, hat beim KI Klub Werder gezeigt, wie man einen produktionsreifen lokalen LLM-Stack aufsetzt. Von Hardware-Entscheidungen über Docker-Setup bis zu MCP-Integrationen – hier ist, was du wissen musst.
Warum lokal statt Cloud?
Die Motivation ist simpel: Datenkontrolle. Bei Cloud-Services wie ChatGPT oder Claude verlassen deine Daten bei jeder Anfrage deine Infrastruktur. Das erzeugt nicht nur DSGVO-Risiken und AI-Act-Pflichten, sondern schafft auch strategische Abhängigkeiten.
Lokale LLM-Infrastrukturen lösen alle diese Probleme:
- Keine Drittlandstransfers: Daten bleiben in deinem Netzwerk
- Compliance by Design: DSGVO, AI Act und Data Act werden einfacher
- Keine API-Kosten: Einmalige Hardware-Investition statt monatlicher Abos
- Minimale Latenz: Keine Netzwerk-Roundtrips
- Volle Kontrolle: Modelle, Konfiguration, Tool-Integration – alles in deiner Hand
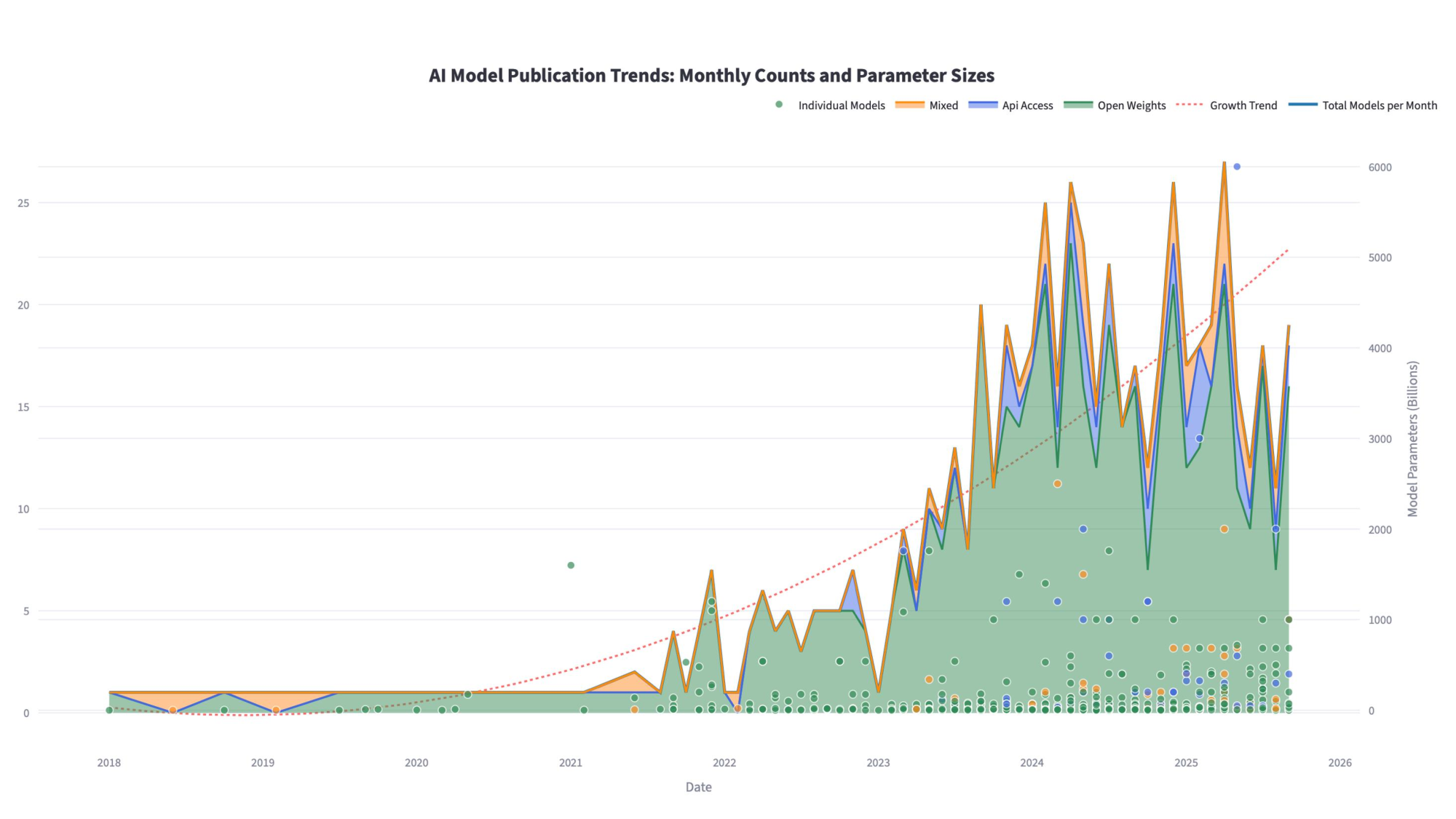
Gleichzeitig wächst die Menge von Open Source/Open Weight Modellen, die immer fähiger werden. Wer braucht schon die Kapazität von Claude oder ChatGPT, um ein Meetingprotokoll zu erstellen, wenn Qwen3 dies mit einem Bruchteil der Parameter genauso gut macht?
Der Stack: Pragmatisch und produktionsreif
Florian stellte einen bewährten Software-Stack vor, der auf Open-Source-Komponenten basiert:
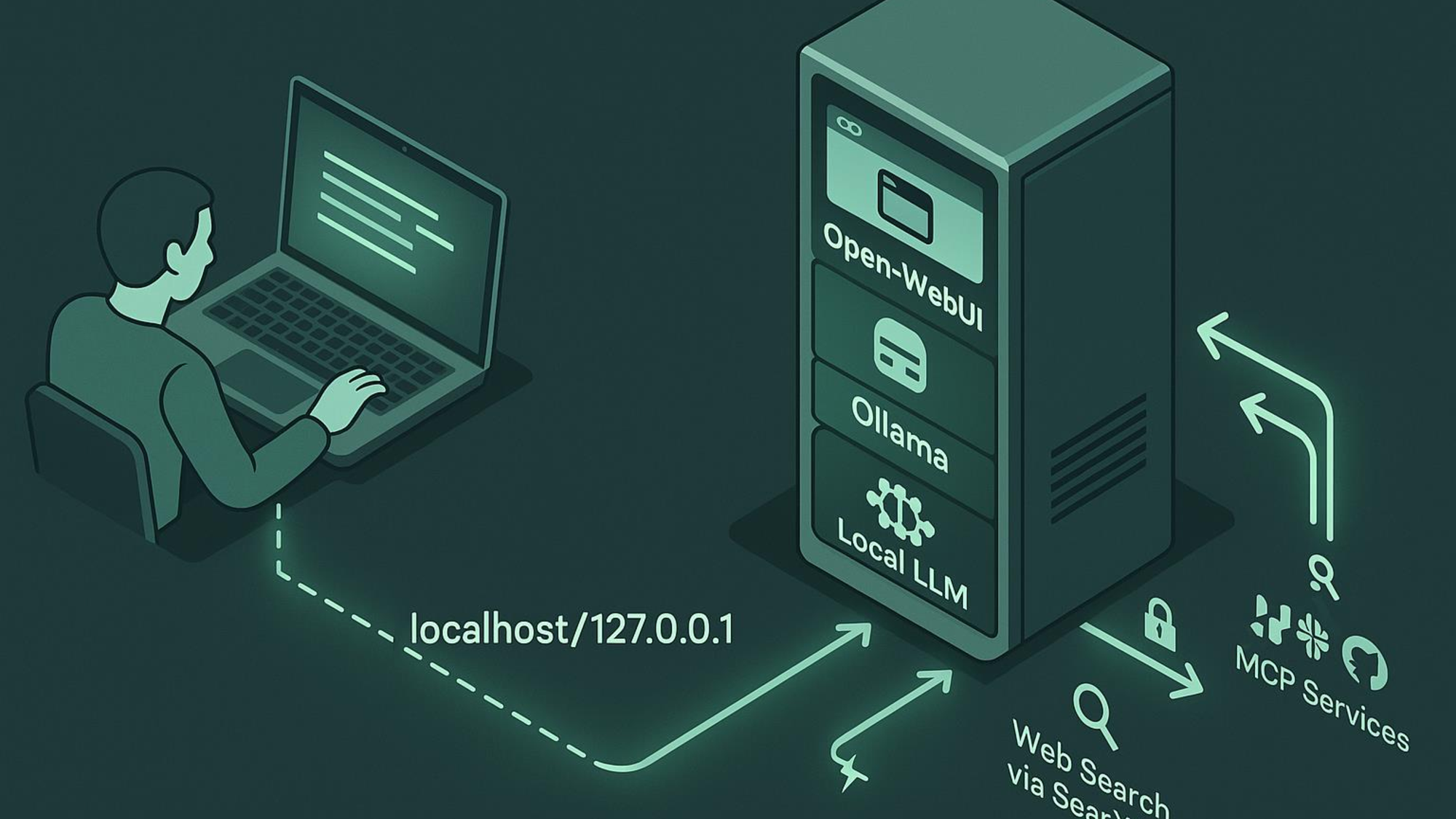
Core-Komponenten
Ollama als Model-Server – Modelle herunterladen und starten mit einem simplen ollama pull. Keine komplexe Konfiguration, keine API-Keys, funktioniert super einfach.
Open-WebUI als Benutzeroberfläche – sieht aus wie ChatGPT, funktioniert wie ChatGPT, ist aber komplett lokal. Perfekt für kleine Teams.
Docker für Integrationen – alle Services containerisiert, einfach zu deployen, einfach zu warten.
MCP-Integration: Tools, die du kennst
Das Model Context Protocol (MCP) von Anthropic ermöglicht die kontrollierte Integration externer Tools:
- Confluence: Interne Dokumentation durchsuchen
- Jira: Ticket-Status und Sprint-Informationen abrufen
- SearXNG: Private Web-Suche ohne Tracking
- Docling: PDF- und Dokumenten-Verarbeitung
Und Qdrant: als Vector-Store für RAG (Retrieval-Augmented Generation) direkt per Docker in Open-WebUI integriert.
Der Clou: Alle Tool-Zugriffe laufen über kontrollierte Endpunkte. Du definierst, welche Systeme das LLM erreichen darf.
Architektur: Daten bleiben drinnen
Der fundamentale Unterschied zwischen Cloud und lokal wird in der Architektur sichtbar:
Cloud-Workflow:
- Anfrage verlässt dein Netzwerk
- Verarbeitung bei OpenAI/Anthropic/Google
- Tool-Aufrufe über deren Infrastruktur
- Antwort zurück
Lokal-Workflow:
- Anfrage an die lokale Infrastruktur
- Inferenz auf deiner GPU
- Tool-Aufrufe über interne Endpunkte (wenn du es erlaubst)
- Antwort lokal generiert
Ergebnis: Keine Daten bei Dritten, keine heimlichen Trainingsdaten-Sammlung, keine unnötigen Logs bei Big Tech.
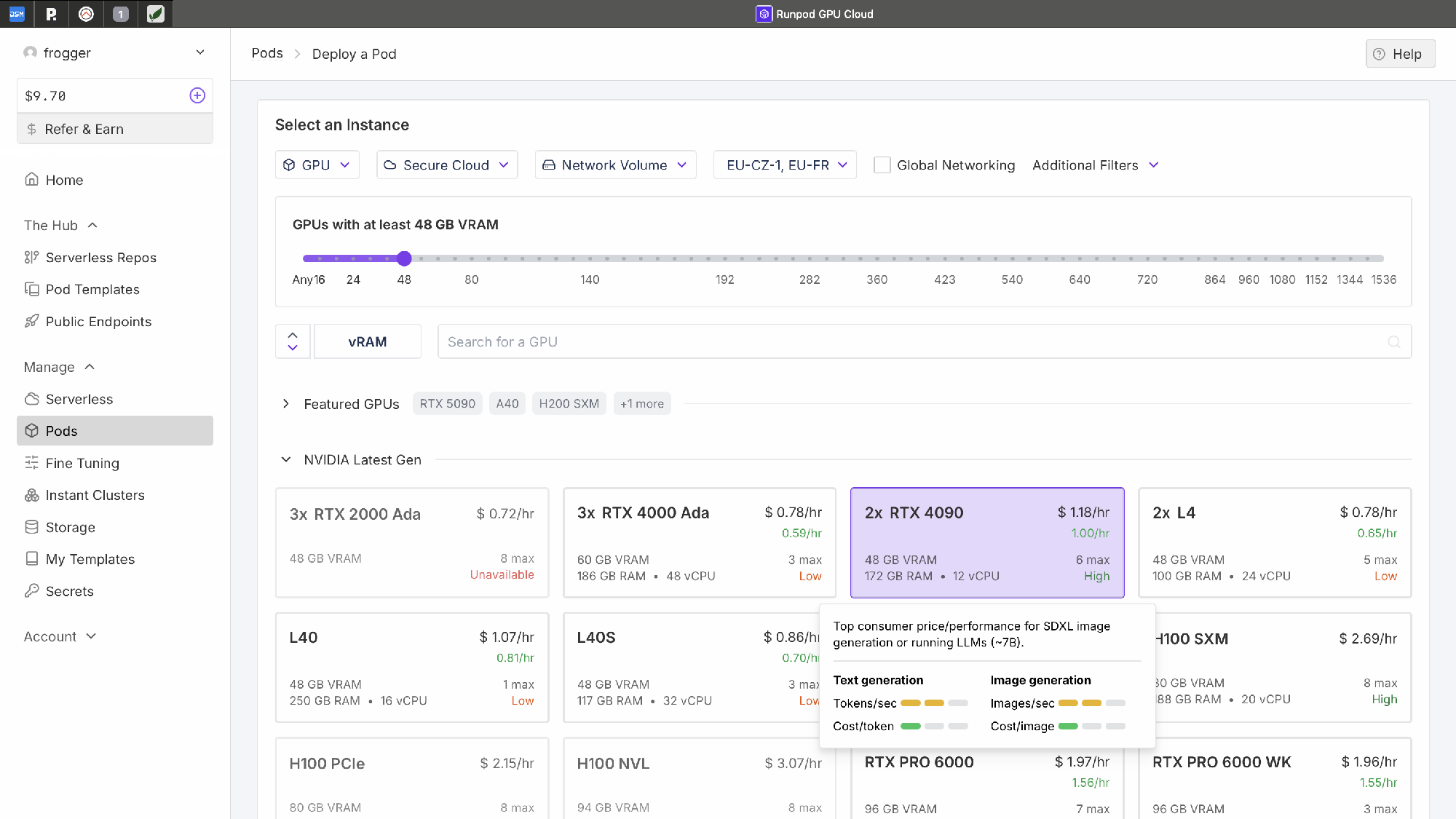
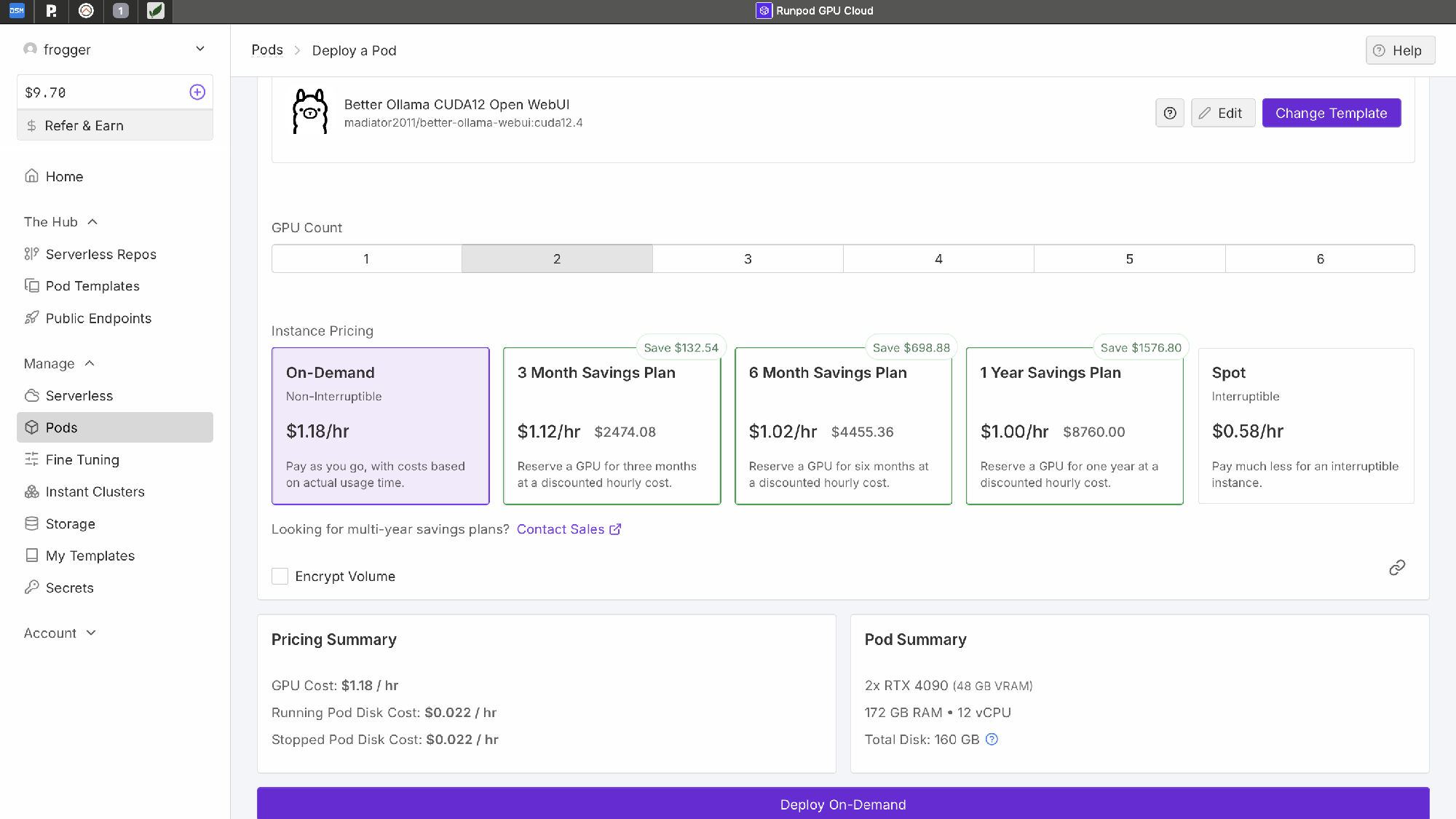
Hardware: Realistisch planen
LLMs basieren auf massiv parallelen Berechnungen – GPUs sind Pflicht. Florians Empfehlungen basieren auf praktischer Erfahrung:
Der Sweet Spot:
- 24GB VRAM (z.B. RTX 3090): Läuft Modelle mit 7B-13B Parametern nativ, bis ~30B quantisiert
- 48GB VRAM (z.B. 2x RTX 3090): Für ~32B-Modelle mit großem Kontext optimal
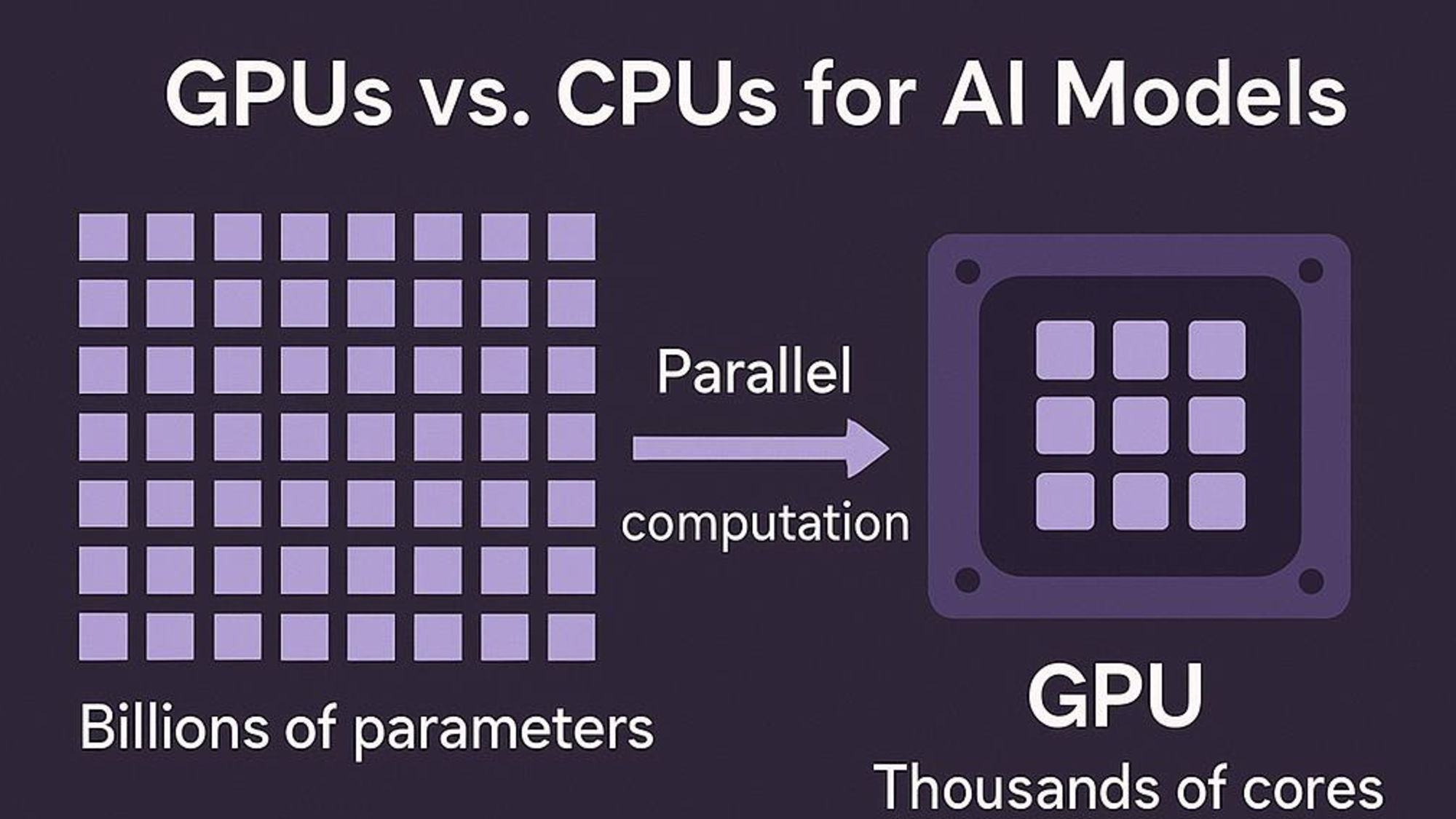
Warum GPU statt CPU? LLMs bestehen aus Milliarden Parametern, die parallel verarbeitet werden. GPUs haben tausende Kerne für genau solche Operationen – CPUs nur wenige Dutzend. Der Performance-Unterschied ist dramatisch.
Florian zeigte auch seinen eigenen Aufbau: Custom-PC mit Wasserkühlung, optimiert für Dauerbetrieb. Eine Investition von ca. 3.500 EUR für eine ernsthaft produktiven Setup.
Präsentation: Self-Hosted LLM Stack









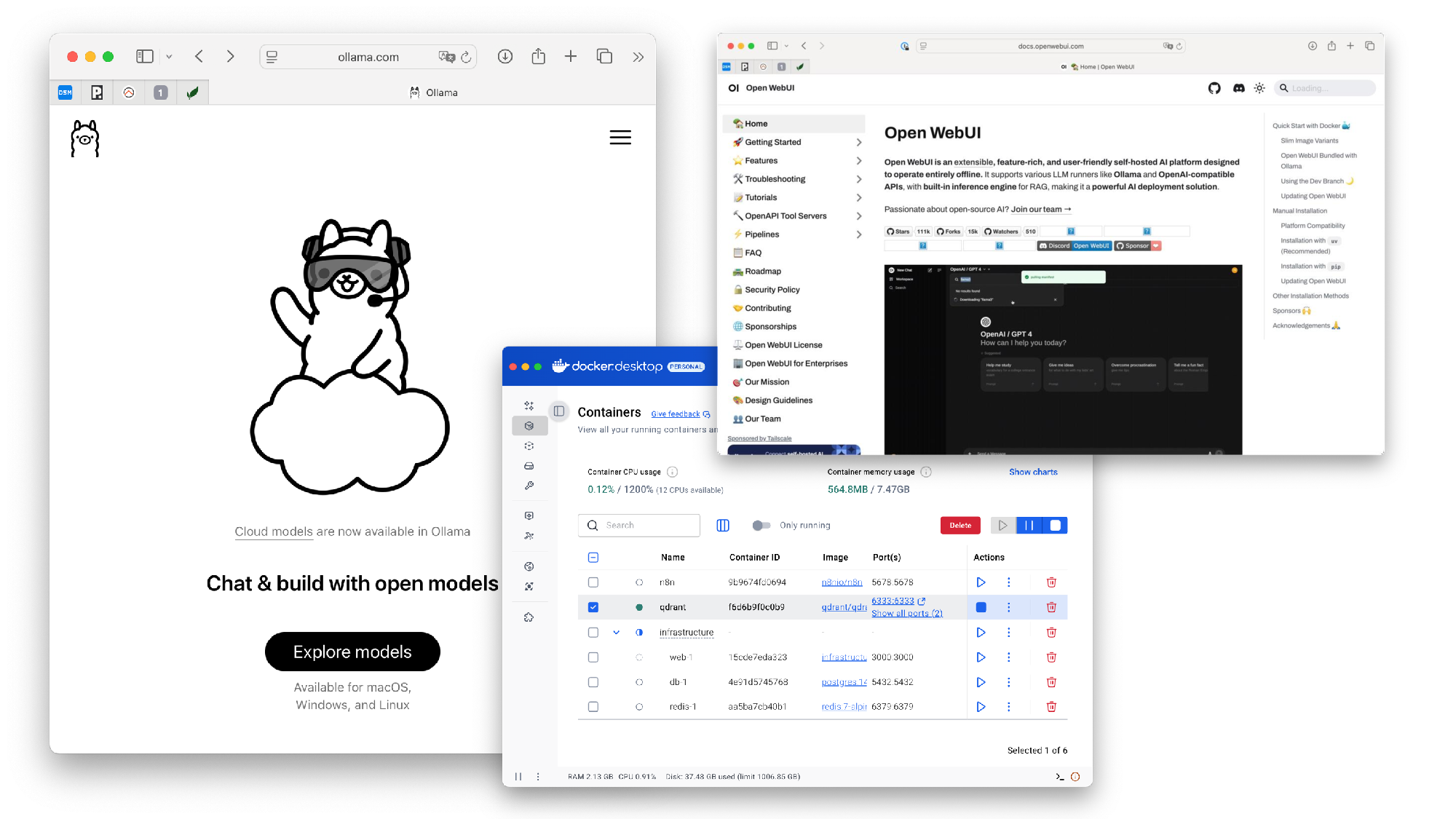

Live-Demo: Praxis, die trägt
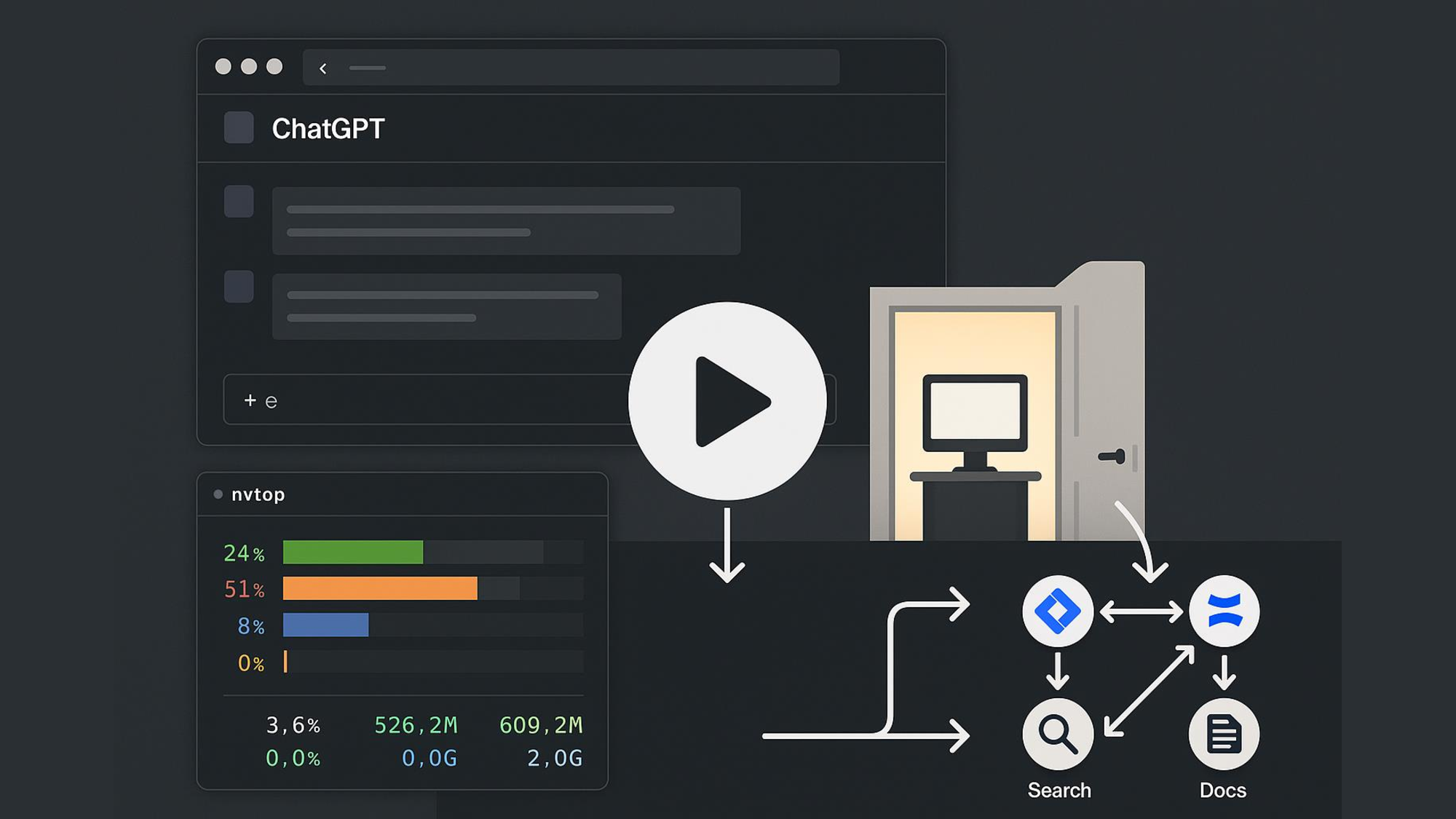
Die Demo zeigte, was das System leistet:
- Monitoring mit nvtop: Echtzeit-Übersicht über GPU-Auslastung, VRAM-Nutzung und Temperatur
- PDF-Analyse: Dokument hochladen, vom LLM analysieren lassen
- Confluence-Integration: "Hole mir die neueste Dokumentation zu Projekt X"
- Jira-Abfrage: "Welche Tickets sind aktuell in Sprint 23?"
- Web-Recherche: SearXNG für aktuelle Informationen über viele Suchmaschienen ohne zu tracken
Bedienung: Genau wie ChatGPT – nur eben mit voller Datenkontrolle und revisionssicher.
Compliance: By Design statt by Contract
Ein lokaler Stack vereinfacht Compliance erheblich:
DSGVO:
- Datenminimierung: Daten verlassen nie deine Infrastruktur
- Zweckbindung: Du definierst, wofür das LLM genutzt wird
- Betroffenenrechte: Alle Daten liegen bei dir, Auskunft/Löschung ist trivial
AI Act:
- Dokumentation: Logge Prompts und Antworten in deinem System
- Risiko-Klassifizierung: Einfacher, weil du den kompletten Stack kontrollierst
Data Act:
- Portabilität: Deine Daten, dein Format
- Wechselrechte: Kein Vendor Lock-in
Ausblick: Von Chat zu Agenten
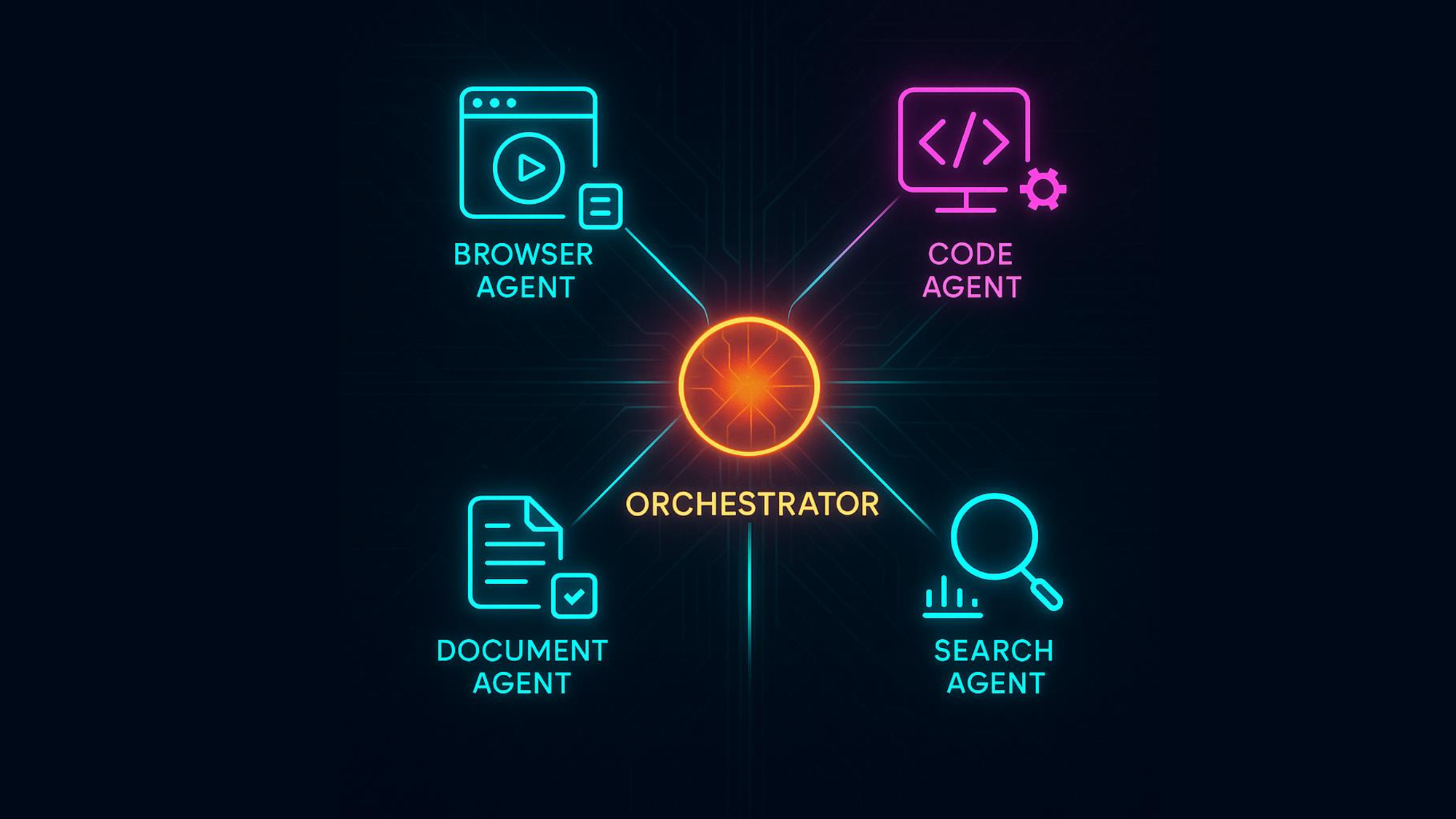
Florian zeigte zum Abschluss eigent.ai – ein Multi-Agent-System, das auf CAMEL-AI basiert. Statt einzelner Chat-Anfragen orchestriert eigent.ai mehrere spezialisierte Agents:
- Browser Agent: Web-Automatisierung
- Code Agent: Schreibt und führt Code aus
- Document Agent: Erstellt strukturierte Dokumente
- Search Agent: Multi-Source-Recherche
Der Orchestrator zerlegt komplexe Aufgaben, verteilt sie an spezialisierte Agents und koordiniert parallele Ausführung. Alles lokal, mit klaren Policies.
Das ist die nächste Stufe: Von reaktivem Chat zu proaktiver Automatisierung – und das ganze auf Deinen eigenen Systemen.
KI Klub Werder (Havel)
Wir zeigen dir jeden Monat hands-on, wie Datenautonomie mit KI geht. Bring deinen Laptop mit, nimm dein Modell mit nach Hause.
Zu den Veranstaltungen →